

Multi-headed Self-attention

In a translation model, the following sentence is an input we want to translate:
‘‘The animal didn't cross the street because it was too tired.”
As the model processes each word (each position in the input sequence), self-attention allows the model to look at other positions in the input sequence for clues that can help lead to a better encoding for this word. For e.g., self-attention allows it to associate “it” with “animal”.
Self-attention Steps
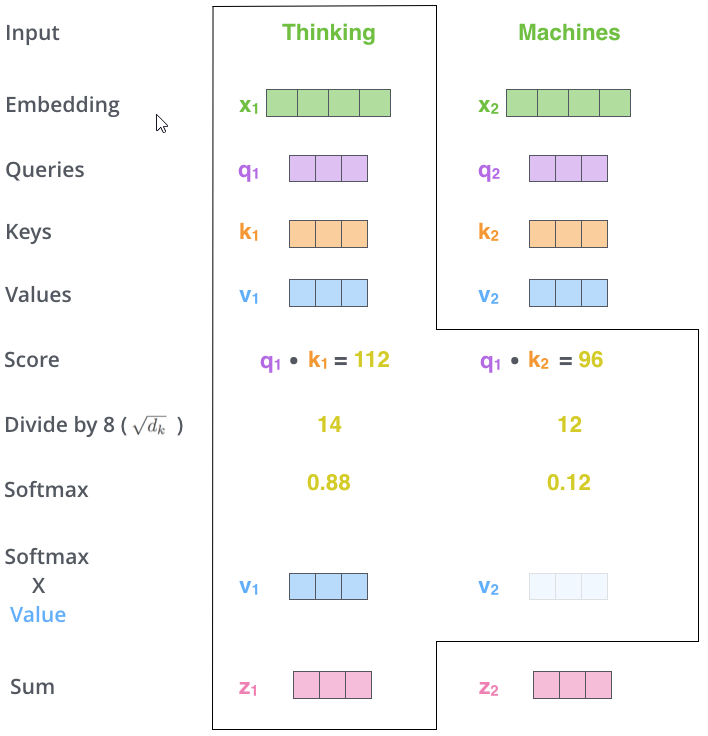
Query, Key and Value vector
For each word, we create a Query vector, a Key vector, and a Value vector.
These vectors are created by multiplying the embedding or vectors from lower encoders by three matrices (WQ, WK, WV) trained during the training.
Scoring
It determines how much focus to place on other parts of the input sentence as we encode a word at a certain position.
The score is calculated by taking the dot product of the query vector with the key vector of the respective word we’re scoring.

Stable Gradients and Normalization
Divide the scores by the square root of the dimension of the key vectors.
Softmax normalization of the scores so they’re all positive and add up to 1. The softmax score determines how much each word will be expressed at this position.
Self-attention Weights
Multiply each value vector by the softmax score. This is to keep intact the values of the word(s) we want to focus on and drown-out irrelevant words.
Sum up the weighted value vectors. This produces the output of the self-attention layer at a particular position.
Matrix Formulation
Calculate the Query, Key, and Value matrices by packing our embeddings into a matrix X and multiplying it by the weight matrices we’ve trained (WQ, WK, WV).

The rest of the steps can be condensed in one formula to calculate the outputs of the self-attention layer.

Multi-headed
With multi-headed attention we have not only one, but multiple sets of Query/Key/Value weight matrices. This expands the model’s ability to focus on different positions and gives the attention layer multiple “representation subspaces”.
Here, we do the same self-attention calculation many times with different weight matrices, we end up with different Z matrices. The feed-forward layer is expecting a single matrix (a vector for each word). So, we concatenate the matrices then multiply them by an additional weights matrix WO.
